

Netflix's Counter Abstraction: A Hidden Gem for System Design Interviews
Learn how Netflix counts billions of events and why you should care

While a lot of system design is about clever arrangement of the right pieces into the right configuration, some problems are bottomless sources of questions from interviewers. Counting events at scale is a surprisingly deep topic that can really set you apart in system design interviews. For this newsletter we’ll break down Netflix's approach to this deceptively complex problem and how understanding it can elevate your next system design interview.
The Netflix TechBlog post is here!
The Challenge: Counting Is Hard (No, Really)
Counting seems trivial, right? Just increment a number! But at Netflix scale (or any large system), it becomes fiendishly complex:
Contention: Multiple services trying to update the same counter simultaneously
Consistency: Ensuring counts are accurate across regions
Cost: Managing infrastructure costs for potentially millions of counters
Idempotency: Ensuring retries don't lead to over-counting
In interviews, most candidates propose simple solutions: "Let's just use Redis incr/decr commands!" But this reveals a junior understanding of distributed systems. Senior engineers understand the tradeoffs involved and notice the bottlenecks around the corner.
Approaches That Will Impress Your Interviewer
Netflix's counter abstraction offers three approaches, each with different tradeoffs. Understanding these will equip you to discuss counting problems intelligently in an interview. In this case let’s focus on counting events where we typically want to know how many events happened in a particular time (clicked a button, watched a video, etc).
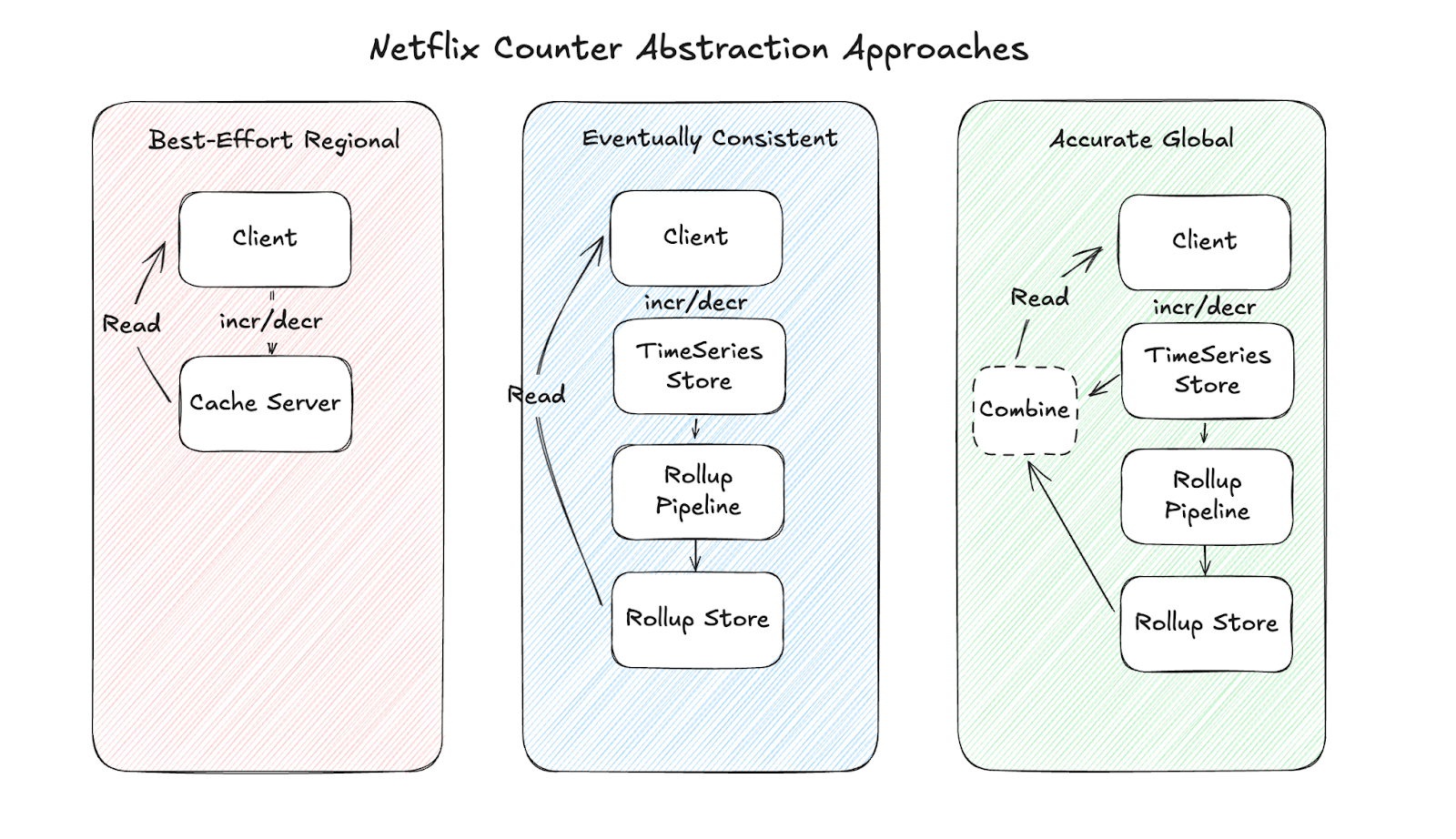
1. Best-Effort Regional Counter
Sometimes, the simple approach is actually good enough. Netflix's Best-Effort Regional Counter approach leverages their EVCache system, which is built upon Memcached. At its core, this approach embraces simplicity over complexity. When a service needs to increment a counter, it sends a request to EVCache with a namespace and counter name combined into a unique key. EVCache then applies a straightforward increment or decrement operation depending on whether the delta value is positive or negative. This operation happens atomically within a single cache node, determined by consistent hashing of the counter key.
The beauty of this approach lies in its performance characteristics. Since EVCache operates entirely in memory, these operations complete in microsend timeframes, allowing Netflix to process hundreds of thousands of counter updates per second within a region.
However, this approach accepts several compromises in exchange for its speed. There's no durable storage backing these counters, meaning server failures or restarts can lose count data entirely. When multiple regions are involved, each region maintains its own independent counter values with no cross-regional replication for increment operations. This regional isolation makes it impossible to get a truly global view without additional aggregation systems. Furthermore, the approach lacks idempotency controls, so retry attempts from clients can lead to double-counting in failure scenarios.
The load distribution across the EVCache cluster happens naturally through consistent hashing of counter keys. This distributes different counters to different nodes in the regional cluster, allowing the system to scale horizontally as counter cardinality increases. However, extremely popular counters can still create hot spots on individual nodes.
Netflix employs this simpler approach primarily for analytics scenarios like A/B testing, where absolute precision isn't critical and the emphasis is on high throughput and minimal latency.
When to recommend this: For scenarios where approximate counts are acceptable (A/B testing, feature usage tracking) and performance is critical.
Tradeoffs to mention: No cross-region replication, no idempotency, potential data loss during failures. But you get extremely low latency and great throughput.
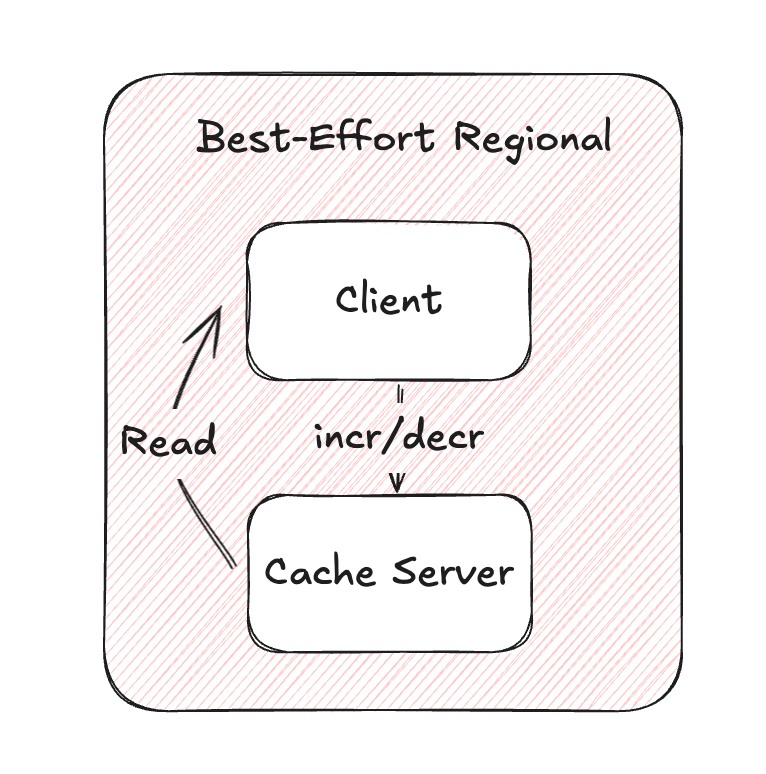
2. Eventually Consistent Global Counter
Netflix's Eventually Consistent Global Counter takes a fundamentally different approach by focusing on durability and accuracy at the expense of some latency. Rather than directly incrementing a counter value, this approach stores each individual counting event as an immutable record in their TimeSeries Abstraction, which is backed by Cassandra. Each counter event includes the counter namespace, name, delta value, event timestamp, and a unique event ID that serves as an idempotency token.

When clients need to increment a counter, they submit their request with an idempotency token. The system durably stores this event and updates a "last-write-timestamp" for the counter in a separate Rollup store. If the durability acknowledgment fails, clients can safely retry with the same idempotency token without risking double-counting. Once stored, the system sends a lightweight notification to trigger background aggregation through a rollup process.
The aggregation process is where much of the complexity resides. A dedicated Rollup Pipeline continuously processes these counter events, but deliberately lags behind the current time by a configurable window (typically seconds). This deliberate lag creates an immutable window of time where no new events will arrive, allowing safe aggregation without complex locking mechanisms. The aggregation process scans all events for a given counter since the last rollup timestamp, computes the new count value, and stores this rollup value along with its timestamp in a persistent Rollup store. These rollup values are also cached in EVCache for fast access during reads.
This approach uses multiple in-memory queues to process rollup events in parallel while ensuring the same counter always lands on the same queue to prevent duplicate work. For counters that are accessed frequently, the system keeps them in continuous rollup circulation until they catch up to their latest writes.
The Eventually Consistent model trades immediate consistency for strong accuracy and global availability. While counts may lag behind their absolute latest value by seconds, they're eventually accurate and resilient against network partitions, server failures, and even regional outages. The approach also maintains a complete audit trail of every increment, allowing for historical analysis or recounting if needed.
When to recommend this: When accuracy matters more than low latency, and you need global consistency and idempotency.
Tradeoffs to mention: Higher latency (typically seconds), more complex implementation, but you get strong guarantees about correctness.
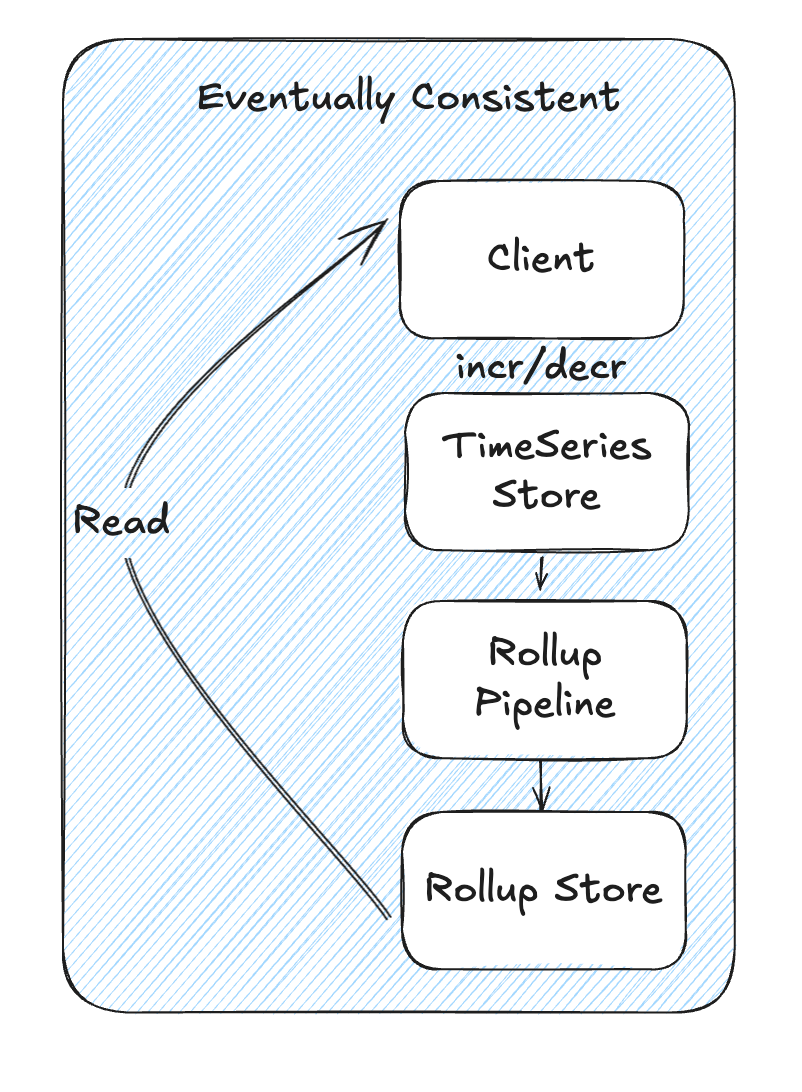
3. Accurate Global Counter
Netflix's experimental Accurate Global Counter builds upon the Eventually Consistent approach but addresses the latency gap by computing real-time deltas. The fundamental storage mechanism remains the same - each counting event is durably recorded in the TimeSeries Abstraction. However, during read operations, the system employs a hybrid approach.
currentAccurateCount = lastRollupCount + (calculate delta since last rollup)
When a client requests the current count, the system first retrieves the most recently rolled-up count value from the Rollup store or cache. It then calculates a delta by scanning all events that have occurred since that last rollup timestamp. By adding this fresh delta to the rolled-up count, the system provides an up-to-the-moment accurate count that doesn't suffer from the intentional lag of the Eventually Consistent approach.
The performance of this approach varies based on the gap between the current time and the last rollup timestamp. If a counter is frequently accessed and remains in active rollup circulation, this gap remains small, resulting in minimal overhead for computing the delta. However, for counters that haven't been accessed recently, calculating the delta might require scanning many time partitions, potentially increasing latency.
To mitigate performance impacts, the system employs similar batching and parallelization techniques as the Eventually Consistent approach. It dynamically adjusts how many time partitions it scans based on the counter's access patterns and cardinality. This adaptive approach helps maintain reasonable performance even for challenging scenarios.
The Accurate Global Counter represents an compromise that provides the strongest accuracy guarantees while minimizing the latency impact compared to the Eventually Consistent approach. It's particularly well-suited for scenarios where precise real-time counts are required but the absolute sub-millisecond performance of the Best-Effort approach isn't necessary.
When to recommend this: For sophisticated use cases requiring near-real-time accuracy with strong consistency guarantees.
Tradeoffs to mention: Higher read latency, more complexity, potentially higher infrastructure costs.
How To Apply This In Your Next Interview
Counting questions invariably involve high scale, lots of contention, and tradeoffs galore: perfect fodder for a system design interview. When asked about counting or metrics in your next system design interview:
Start with understanding requirements - Is eventual consistency acceptable? Do you need global or regional counts? What's the volume and access pattern?
Propose the simplest solution first - Maybe a Redis counter is actually good enough! If it’s not the focus for the problem, move on.
Demonstrate depth by explaining tradeoffs - "We could use Redis for low latency, but we'd sacrifice consistency during failures. Alternatively..."
Scale your solution intelligently - Explain how you'd handle counter hotspots, high cardinality challenges, and retention policies
Remember: Senior+ engineers don't reach for complex solutions unnecessarily. Start simple, then add complexity only when needed and with clear reasoning.
Where This Might Come Up
Counting problems appear in many common interview questions:
Designing analytics systems
Social media engagement metrics
E-commerce inventory and order tracking
Real-time dashboards
Rate limiting systems
Being able to intelligently discuss counting strategies for these scenarios demonstrates a depth of knowledge that most candidates lack.
Conclusion
Netflix's Counter Abstraction shows that even seemingly simple operations like counting become challenging at scale. Understanding these patterns doesn't just help you in interviews—it makes you a better engineer who can build more robust systems.
The strongest system design solutions balance simplicity with practical operational needs. Start simple, understand the tradeoffs deeply, and scale your complexity as required.
Changelog
People are constantly asking us what's new with Hello Interview, so we're going to keep a changelog here to keep you up-to-date. Since our last update:
Platform Updates
We’ve upgraded the backend for our Guided Practice, significantly improving accuracy
New Content
We've got more coming down the pipe that we're excited to share in our next update!
You can vote for what content you want to see next here.
Hi guys in the second approach how are we ensuring the global consistency? Are we assuming the rollup datastores are replicated across regions?
The eventually consistent approach is so elegant for high-scale systems. Great breakdown of the trade-offs!