

The 7 Must Know Patterns for System Design Interviews

When people prepare for coding interviews, it’s universally understood that patterns provide leverage. Nobody tries to memorize the solution to every array or graph problem, the space is simply too large. Instead, candidates build fluency with a core set of data structures and algorithms and then practice recognizing when to apply them. This approach scales. It’s why strong candidates can walk into a completely new problem and still solve them in a short amount of time.
System design should be no different. Yet many candidates approach it as if each prompt is a blank canvas, trying to invent an architecture from scratch in real time. In practice, system design also reduces to a set of recurring patterns: scaling reads, handling contention, managing long-running tasks, and so on. Just as in coding interviews, the key isn’t memorizing past solutions, it’s learning these patterns, understanding their trade-offs, and practicing how to apply them under pressure.
Patterns matter because they give you both language and compression. When you say "this is a contention problem, I'd start with optimistic concurrency" or "this looks like a scaling reads issue, I'd add replicas before reaching for caches", you collapse complexity into a single phrase the interviewer immediately understands. The design space is infinite, but patterns compress that overwhelming landscape into manageable shapes you can quickly recognize, letting you focus on trade offs and decision making rather than reinventing solutions from scratch.
Finally, and maybe most importantly, patterns are evidence of experience. Junior engineers often default to invention, piecing together solutions line by line. Senior+ engineers recognize failure modes instantly because they've lived through them before. That recognition is exactly what interviewers are listening for: fluency over novelty. The ability to say, "I've seen this problem, I know the standard approaches, and here's how I'd adapt one to this case."
So, what patterns show up most often?
We've identified 7 patterns that show up more than any others. If you understand when they apply, what trade offs they carry, and how they combine, you're already most of the way to crushing a system design interview.
1. Scaling Reads
Read traffic often becomes the first bottleneck. Instagram is a classic example: users scroll through dozens of posts, loading hundreds of images and metadata records, but they upload only once a day. The read-to-write ratio can easily reach 100:1.
The progression is straightforward. Start with database optimizations such as indexes, query tuning, or denormalization. Add read replicas to spread the load across multiple servers. Finally, introduce caching where some inconsistency is acceptable.
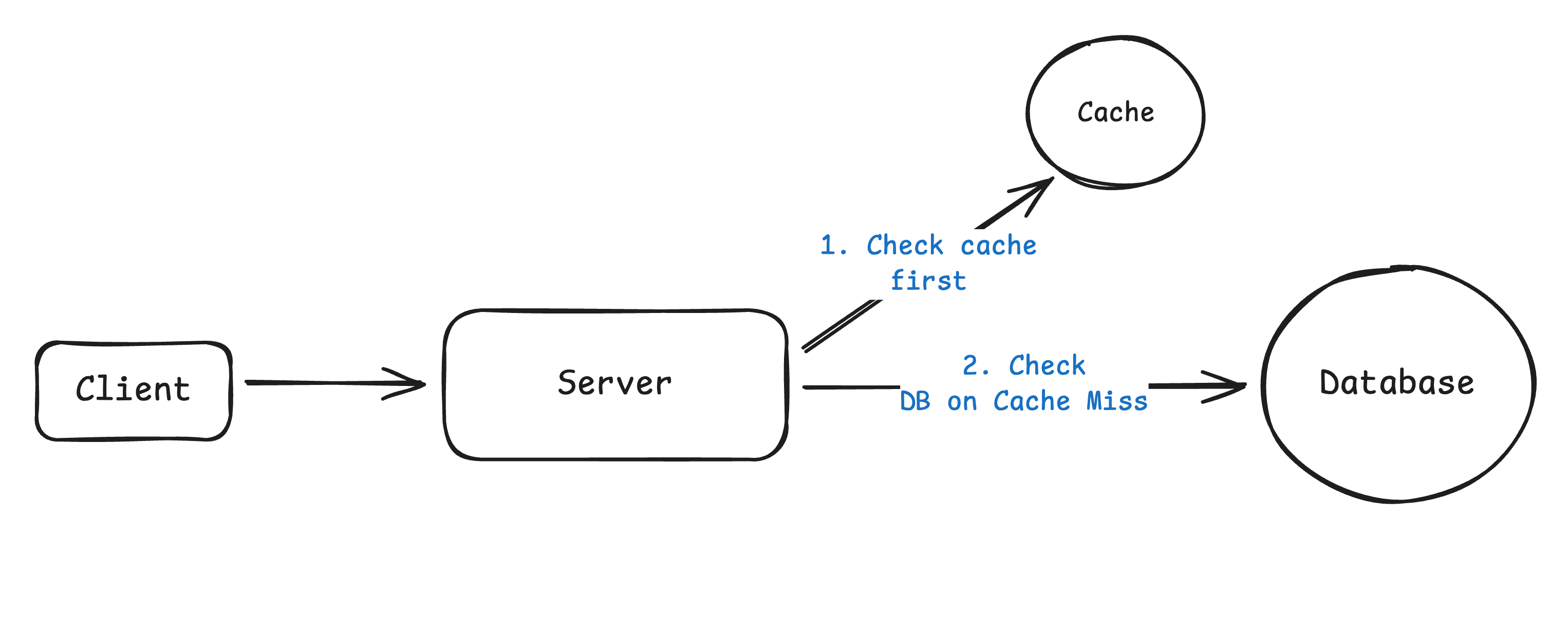
Interviewers expect you to understand the trade-offs. You should be able to talk about cache invalidation, replication lag, and hot keys where many users request the same content at once.
2. Scaling Writes
Scaling writes is harder than scaling reads because every write has to land in the correct place and coordination quickly becomes complex.
The standard approaches are sharding, which splits data across servers, and partitioning, which separates data by type or feature. The challenge is picking keys that balance load while keeping related data together. User IDs work for social feeds, geographic regions for ride sharing, but product categories are a poor choice for e-commerce because some categories dominate traffic.
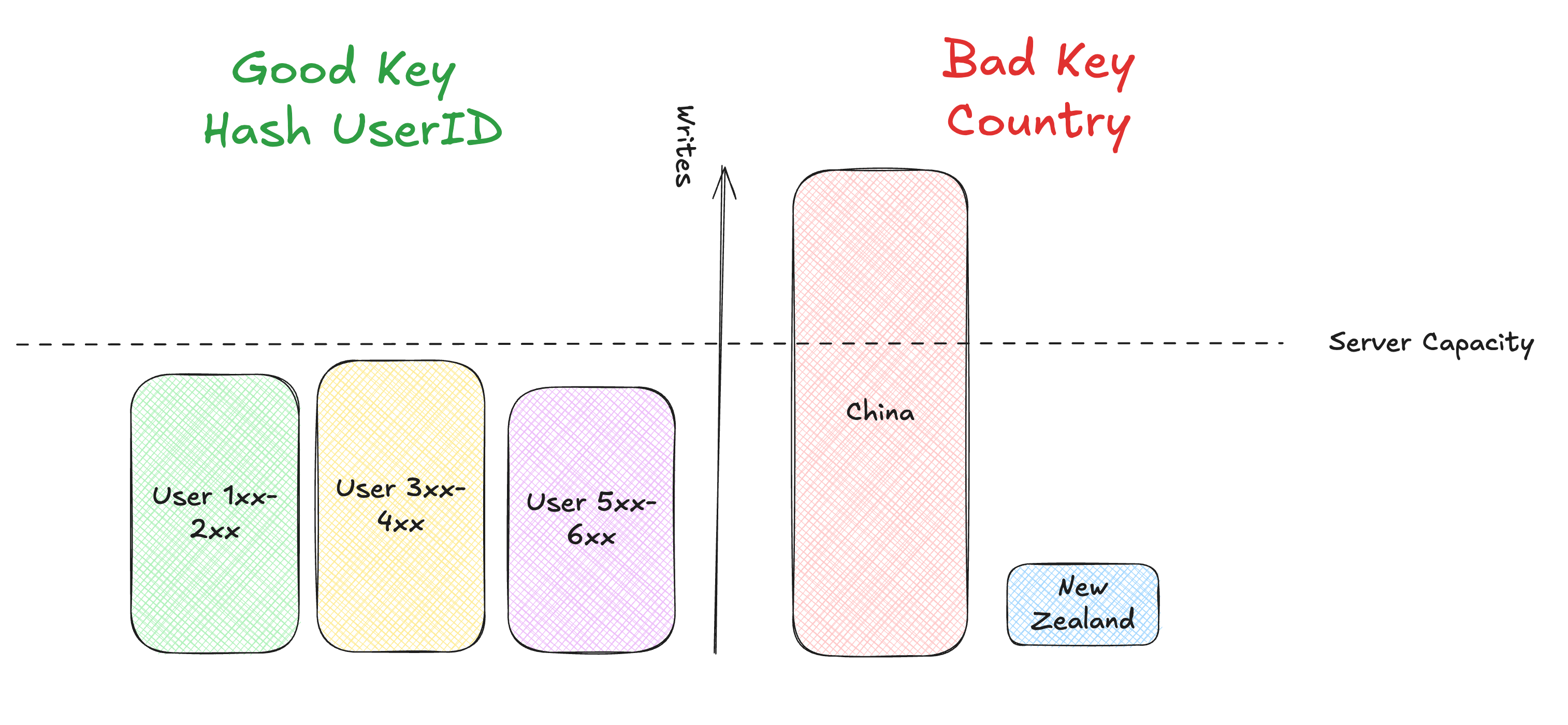
Interviewers will probe how you handle bursts. You should be ready to discuss buffering with queues, the risks of backlog buildup, and when it makes sense to shed load instead of crashing the entire system.
3. Realtime Updates
Many systems need to push updates to users, whether for notifications, chat messages, dashboards, or collaborative editing. The question is how sophisticated the mechanism needs to be.
Polling is the simplest option. Clients ask the server for updates on a schedule, which works everywhere but is inefficient. When polling becomes too expensive, move to server-sent events. For bidirectional communication or very low latency, use websockets.
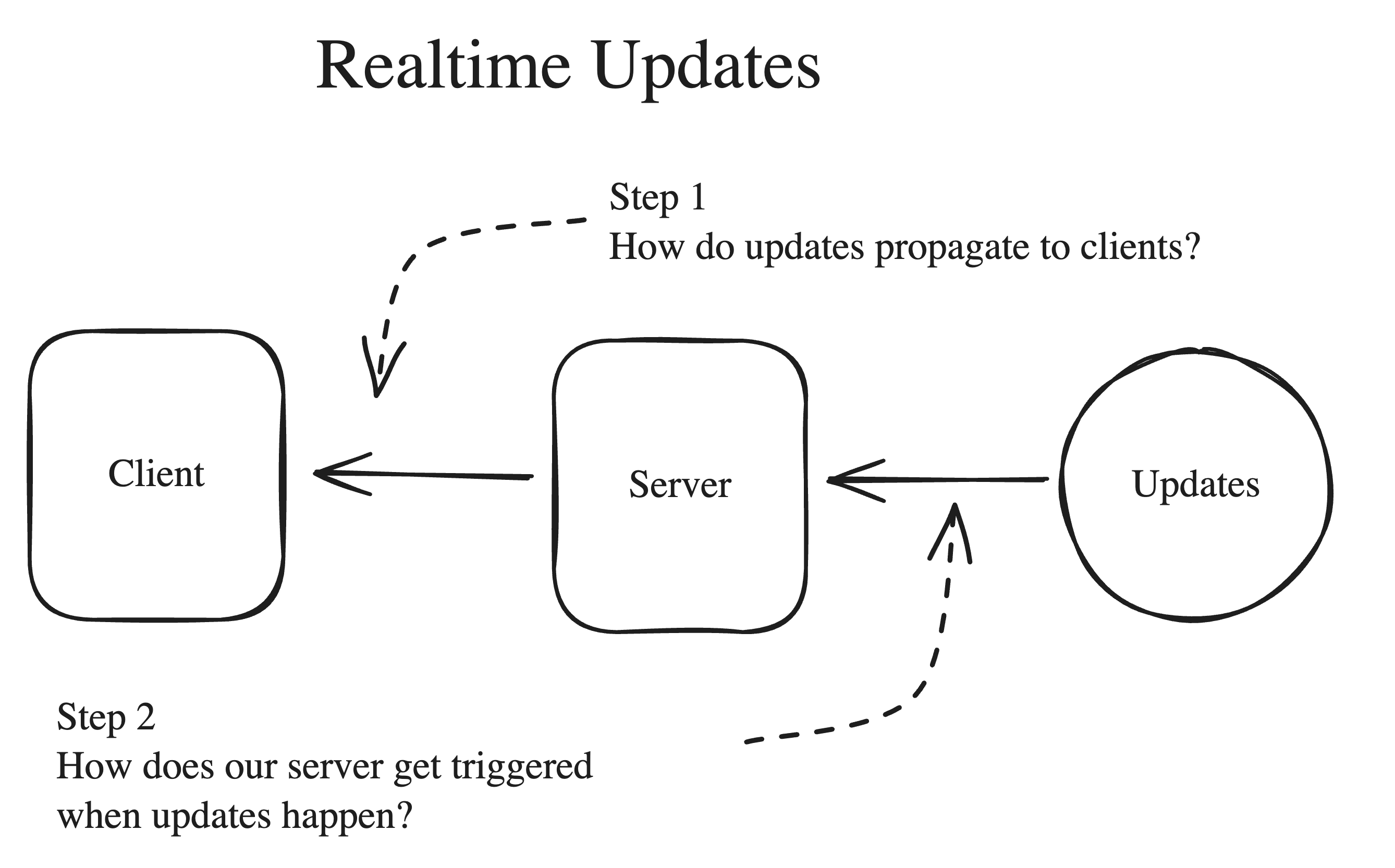
On the backend, pub/sub systems like Redis or Kafka work well for lightweight updates. More complex scenarios such as collaborative editing often require stateful servers and consistent hashing to keep related users on the same machine.
4. Long-Running Tasks
Operations like video encoding, report generation, or bulk data processing take too long to run synchronously. Users should not wait for them, and web servers should not be tied up executing them.
The common pattern is to accept the request, place the job in a queue, and return a job ID immediately. Workers then process the job while the user checks status or receives a callback when it completes.
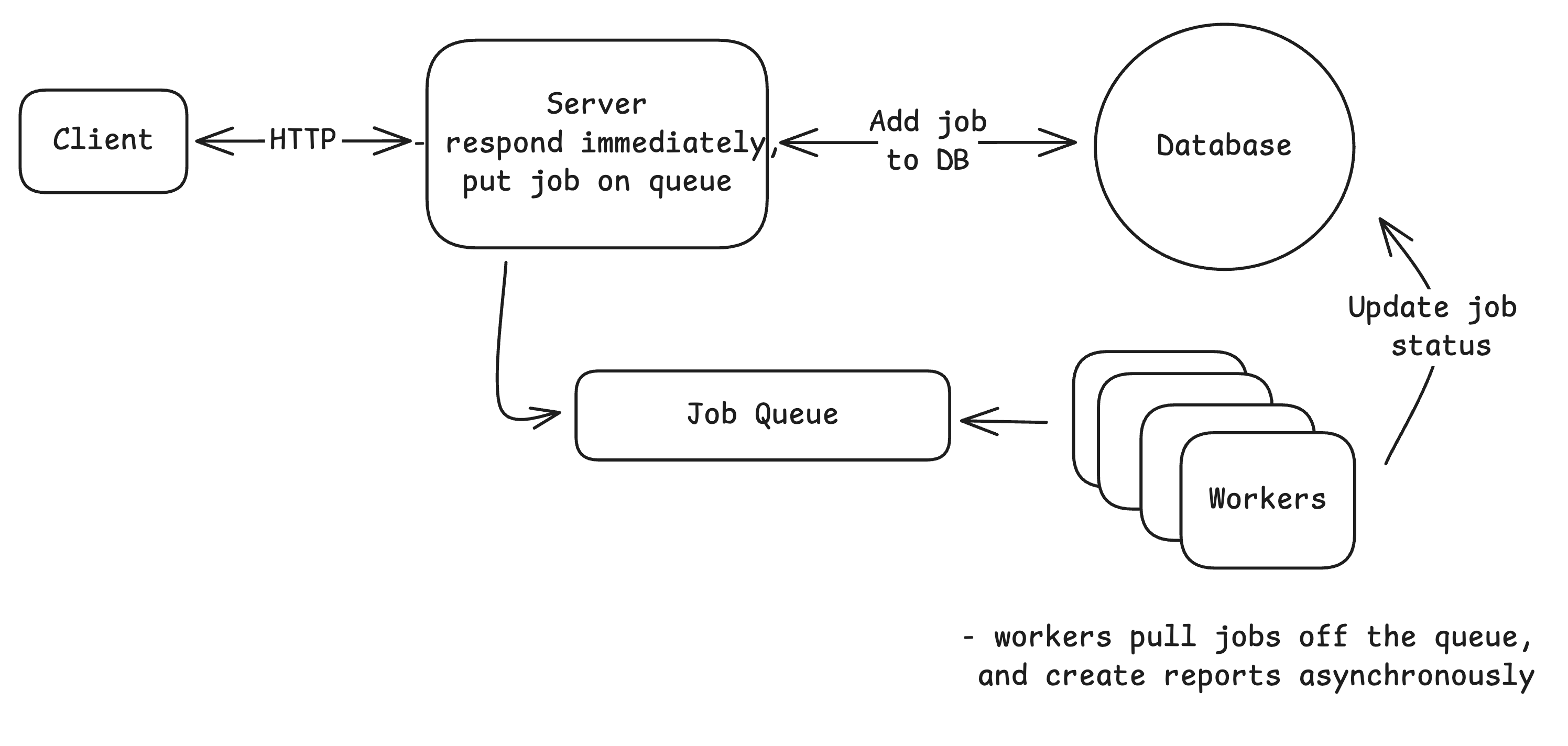
In interviews, it is important to understand trade-offs between different queue technologies. Redis is simple, SQS provides retries and dead-letter queues, and Kafka adds replay capabilities. For workflows with multiple dependent steps, mention systems like Temporal or Step Functions.
5. Dealing with Contention
When multiple users want the same resource at the same time, such as limited tickets or auction bids, you need coordination to avoid race conditions.
Within a single database, transactions and locks usually work. Once data is split across systems, you may need distributed locks or two-phase commits, which add complexity and latency.
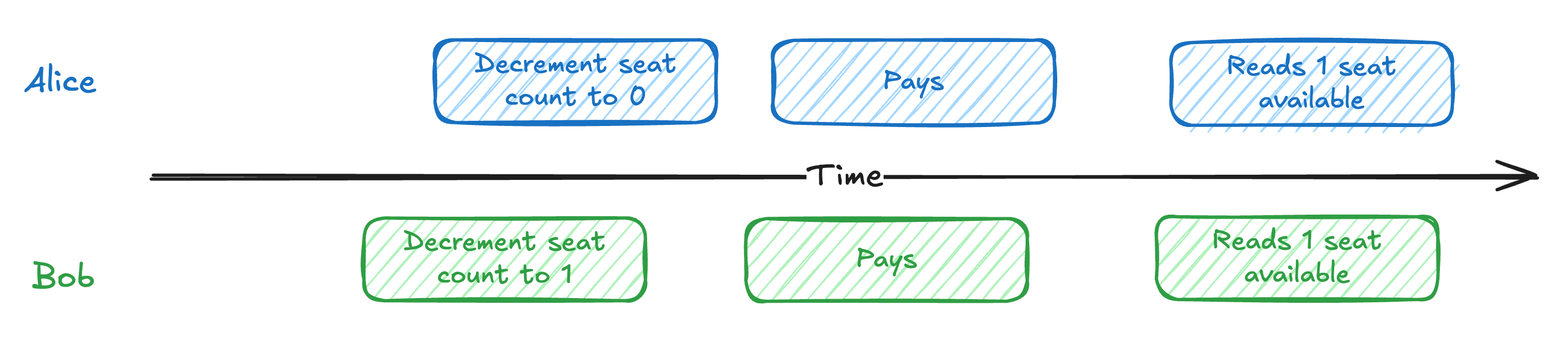
Interviewers will often push on how you would simplify the problem. You might batch requests and process them in waves or collect bids in a time window instead of updating in real time.
6. Large Blobs
Images, videos, and large documents cannot be sent through application servers without overwhelming bandwidth and compute.
The common solution is presigned URLs. The server generates a temporary, scoped URL that lets clients upload directly to storage such as S3. Downloads are served through a CDN, with signed URLs if access control is required.
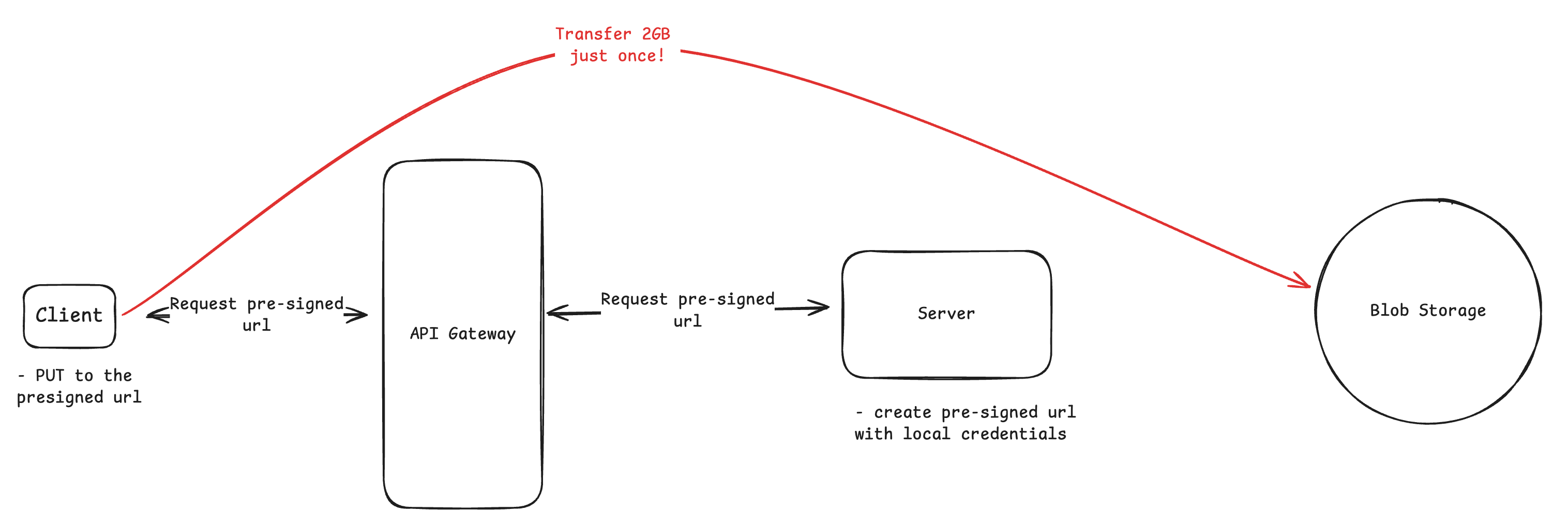
In an interview, expect questions about consistency. You should know how to keep metadata in sync with blob storage, handle failed uploads, and support resumable uploads when needed.
7. Multi-Step Processes
Many workflows span multiple services, such as payment processing, inventory checks, shipping, and notifications. Each step may fail and requires retries or rollbacks.
Simple workflows can be handled with database transactions. More complex ones often need the saga pattern, event sourcing, or workflow engines. These systems provide retries, timeouts, and state management, but they also add operational overhead.
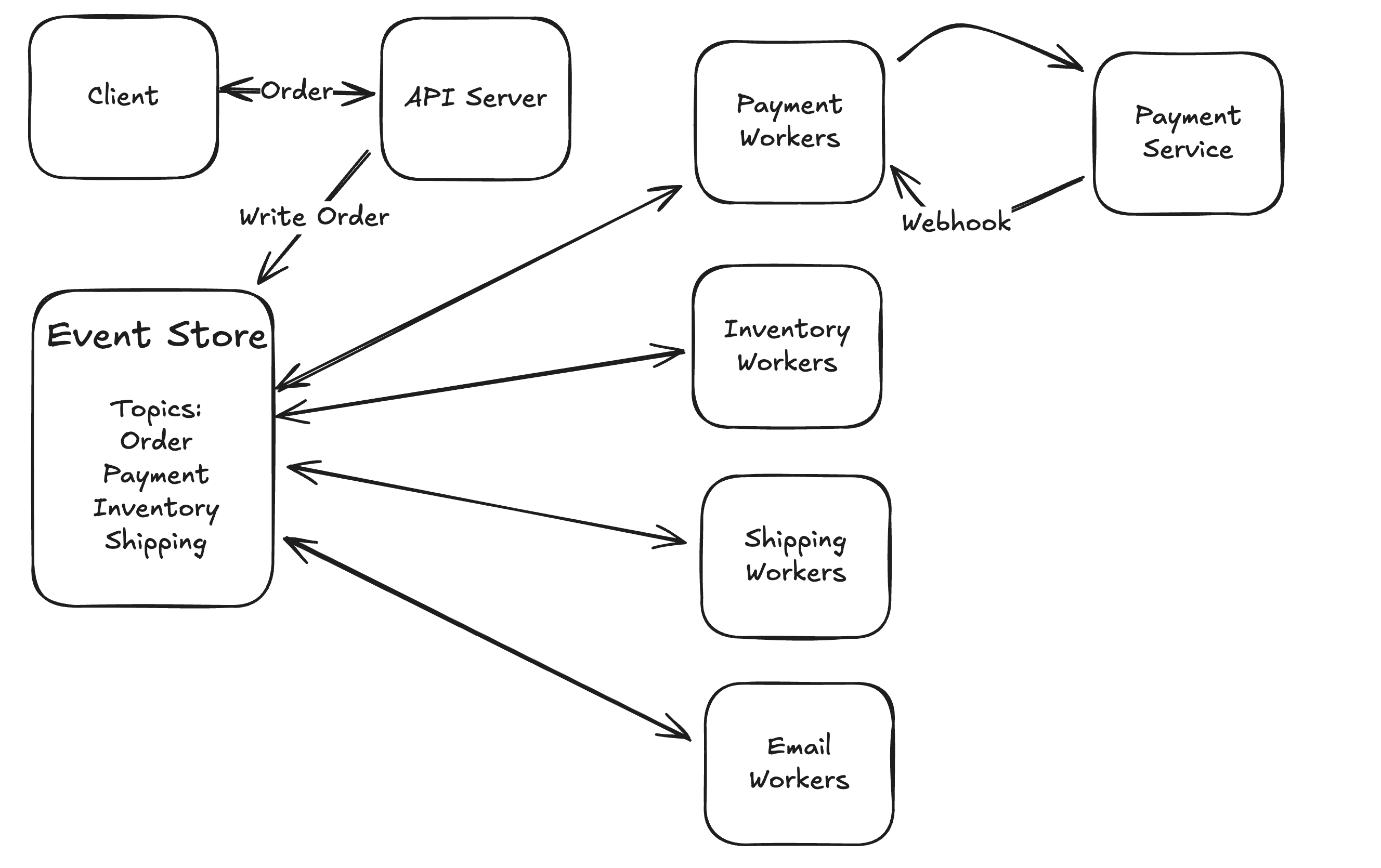
In interviews, what matters is showing you can reason about the right level of orchestration. Sometimes a lightweight approach is enough, and other times a durable workflow system is justified.
Conclusion
Interviewers are not judging whether you can invent a novel architecture in real time. They are looking for fluency, the ability to recognize a familiar shape, recall the relevant patterns, and reason through the trade-offs. That is the mark of a senior engineer, and it is exactly what these interviews are designed to test.
Of course, single patterns are rarely enough. Real systems demand composition. A video platform, for instance, goes beyond file storage; it combines Large Blobs for uploads, Long Running Tasks for transcoding, and Realtime Updates for progress. Strong candidates assemble patterns into coherent architectures that address the full set of requirements rather than stopping at naming individual patterns.
There is a downside to pattern matching! Sometime, there doesn't exist a pattern to solve the problem or, if there does, you don't know it. Being able to switch out of pattern matching and into problem solving mode is a key skill that goes a long way in interviews.
If you understand the seven patterns we’ve covered here, practice recognizing when they apply, and get comfortable combining them, you will already be far ahead of most candidates. Just like with coding, success often comes from pattern recognition, not solution memorization.
Changelog
People are constantly asking us what’s new with Hello Interview, so we’re going to keep a changelog here to keep you up-to-date. Since our last update:
Platform Updates
New Content
Detailed Question Tips and Tricks for Common Interview Questions: Example
We’ve got more coming down the pipe that we’re excited to share in our next update!
thanks for another great article!
> SQS provides retries and dead-letter queues, and Kafka adds replay capabilities
what's the difference between dead-letter queues and replay capabilities? Don't they serve the same end (replaying events that fail)?
++ Good Post, Also, start here how to build tech, Crash Courses, 100+ Most Asked ML System Design Case Studies and LLM System Design
How to Build Tech
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-10-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-06-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-05-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-04-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-03-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-01-the-heart-of?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-02-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
Crash Courses
https://open.substack.com/pub/crashcourses/p/crash-course-09-part-1-hands-on-crash?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-07-hands-on-crash-course?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-06-part-2-hands-on-crash?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-04-hands-on-crash-course?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-03-hands-on-crash-course?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-02-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-01-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
LLM System Design
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-577?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-4ea?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-499?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-63c?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-bdd?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-661?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-83b?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-799?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-612?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-7e6?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-67d?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/most-important-llm-system-design-b31?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://naina0405.substack.com/p/launching-llm-system-design-large?r=14q3sp
https://naina0405.substack.com/p/launching-llm-system-design-2-large?r=14q3sp
[https://open.substack.com/pub/naina0405/p/llm-system-design-3-large-language?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/important-llm-system-design-4-heart?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-63c?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false